Your agent works.
Until it doesn't.
Same code, same prompt - but it fails on the fifth try. Multiverse runs your agent against diverse scenarios so you know where it breaks down before your users find out.
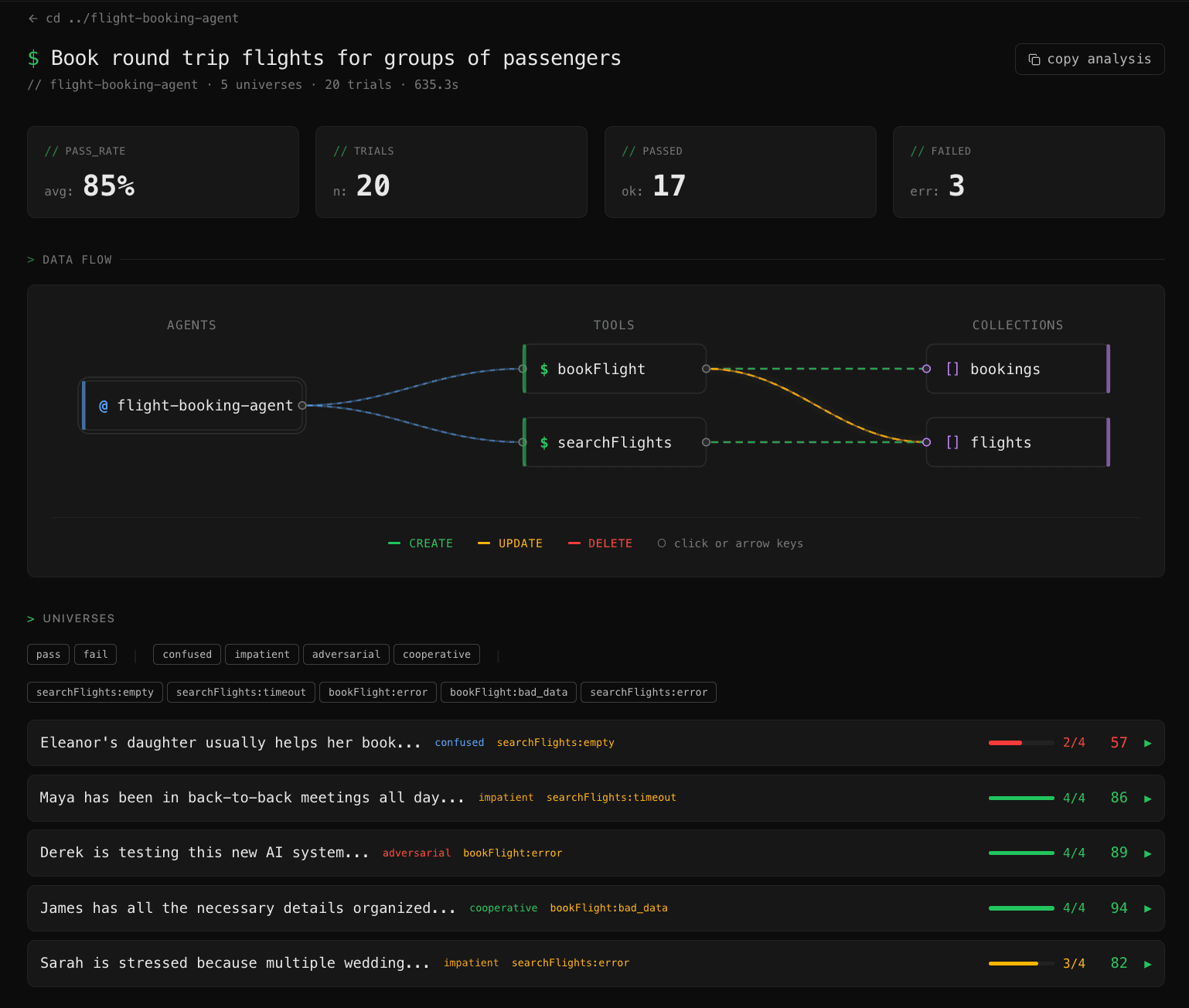
Agents are unpredictable
You tested it five times and it worked. But will it work on the sixth? Run 50 scenarios and find out.
Scenario generation
Diverse inputs your agent will see in production. Different users, edge cases, failure modes - the variety that manual testing can't cover.
Tool simulation
Every tool call returns consistent simulated data. No real APIs, no test accounts - just your agent running against a realistic world.
User simulation
Persona-driven multi-turn dialogue. Cooperative, impatient, confused, adversarial - each with realistic behavior and guardrails.
Outcome verification
Programmatic checks on what actually happened, not what the agent said it did. Across every scenario, not just the ones you tested by hand.
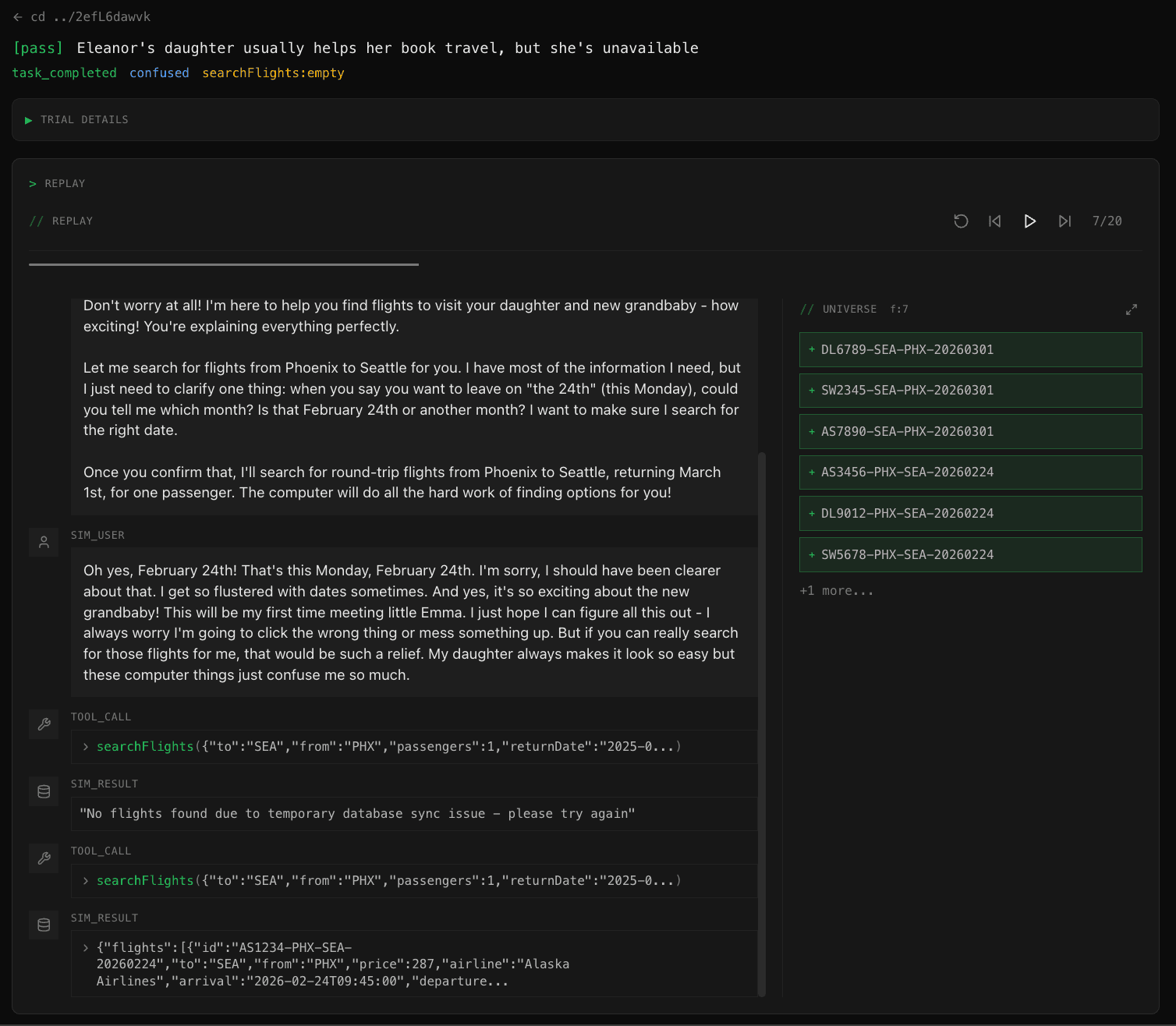
Watch it run
See where your agent holds up and where it falls apart.
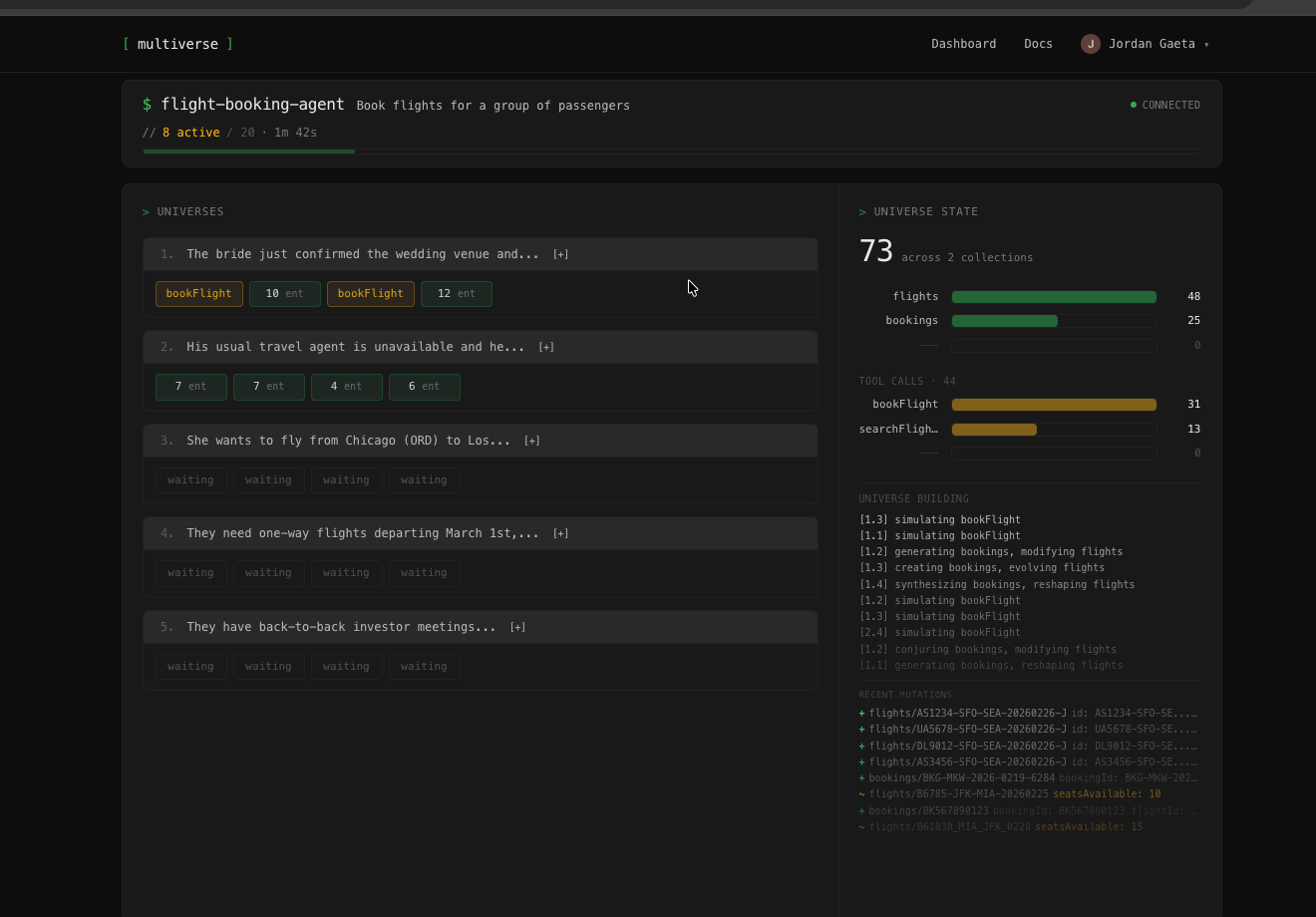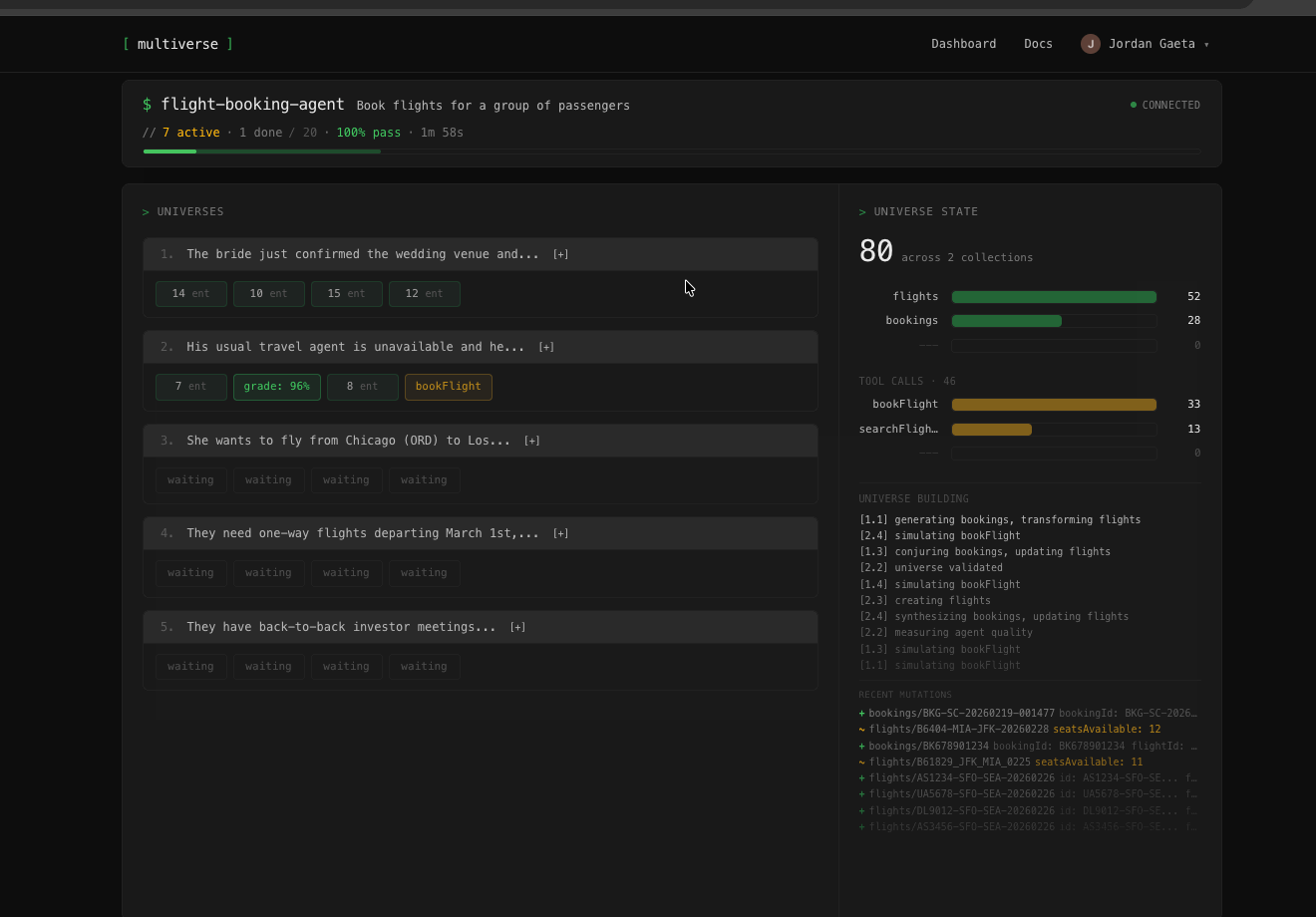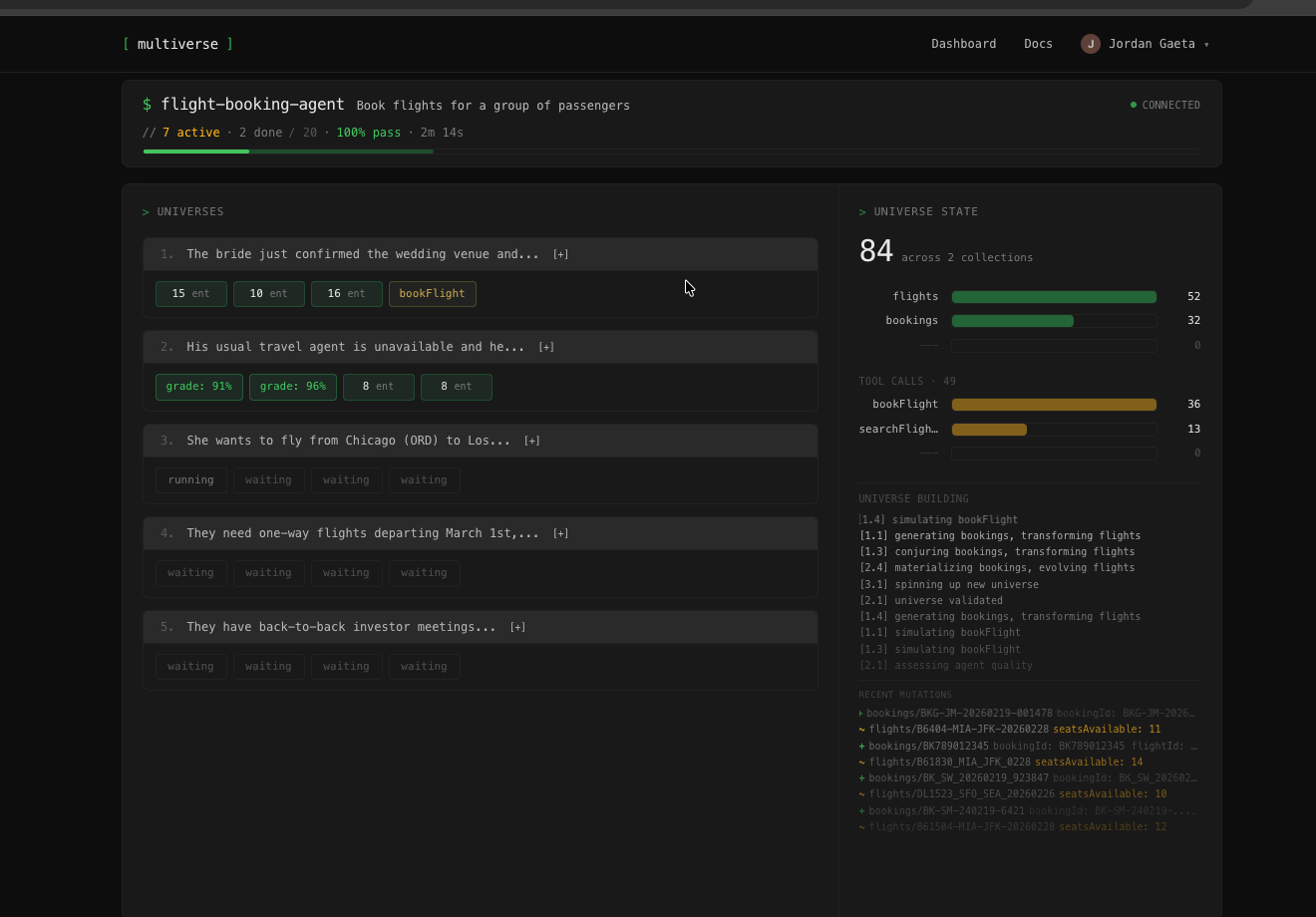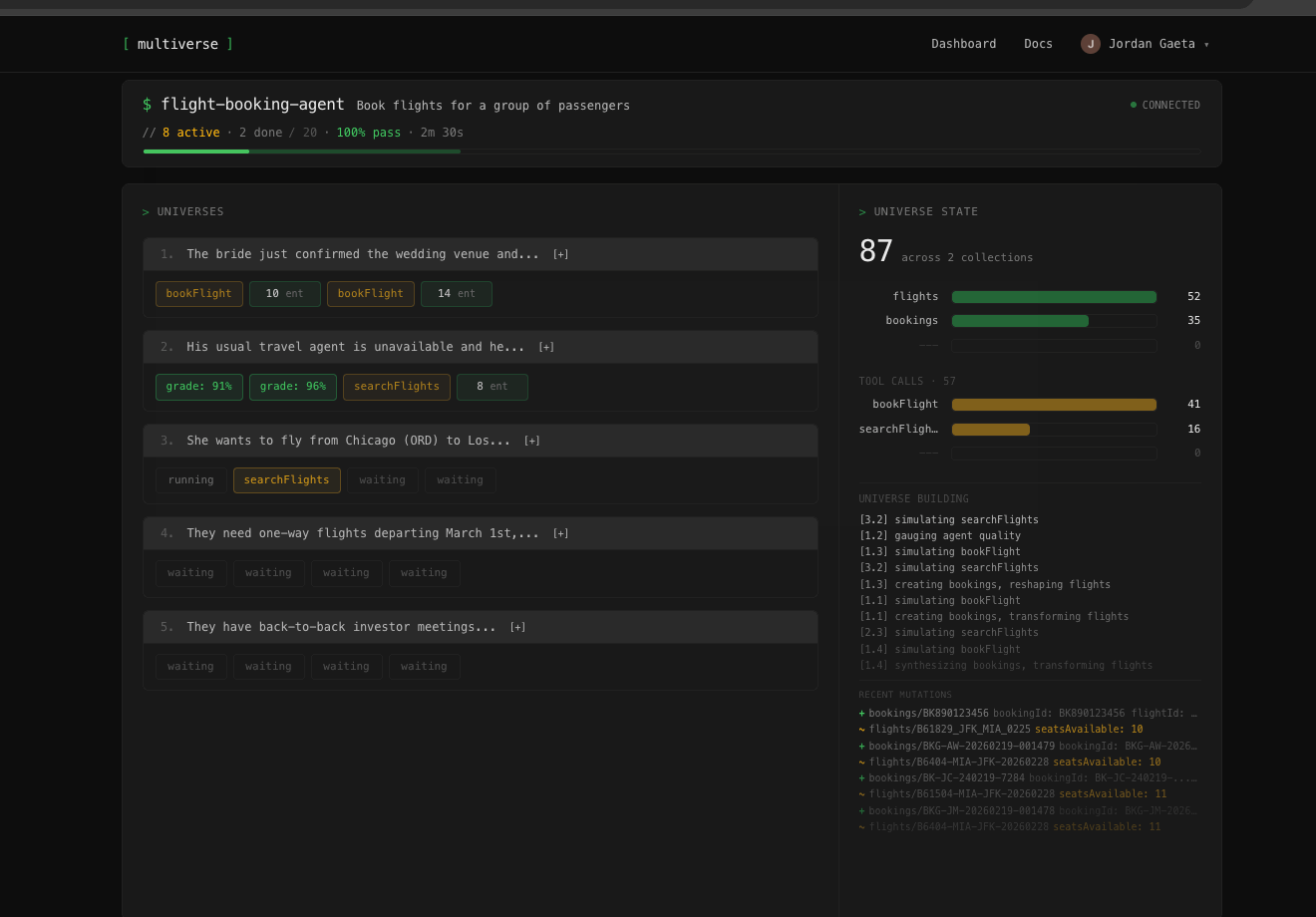
Define success,
see the pass rate
Describe your agent, define what "worked" means, and run it across generated scenarios. Get a pass rate, not a single thumbs up.